Naive Bayes Classifier
The Naive Bayes classifier is a simple algorithm which allows us, by using the probabilities of each attribute within each class, to make predictions. It makes the strong assumption that the attributes within each class are independent, which means that attribute x happening does not influence the probability of y happening. In spite of this strong assumption, Naive Bayes has worked very well in many complex scenarios.
Bayes Theorem
The Naive Bayes algorithm is built upon the Bayes’ theorem which states that the probability of event A occurring given that event B occurs is equal to the probability of event B occurring given that event A occurs times the probability of event A occurring, divided by the probability of event B occurring:
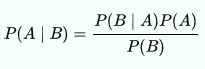
Building a spam filter
Naive Bayes can be used to build a spam filter from scratch. The aim will be, given the words contained in a message, to determine the probability of that message being spam or not. Our equation will be:
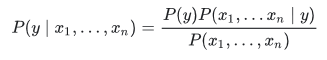
The left part of the equation translates to the probability of the message being spam (y) given the words x1, x2, …., xn. The right part of the equation translates to the probability of a message being spam P(y), times the probability that a spam message contains the words x1, x2, x3, …, xn, divided by the probability that a message (no matter whether it’s spam or not) contains the words x1, x2, x3, …, xn. Given that the attributes (occurrence of the words) are assumed to be independent as stated earlier, the equation becomes:
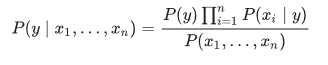
The product of the probabilities of each word occurring can also be written as:
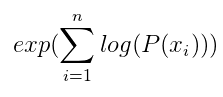
in order to avoid multiplying many probabilities (0 to 1 numbers) together and generating possible underflow.
The data
In this post we will use the data which I found at this link. It contains a text file where each line represents a message. If the line begins with ham then this wasn’t a spam message, whereas if it begins with spam then this was a spam message:

Building the Naive Bayes class
The first method we need to add to our class is a function to extract single words from a message. We can use a simple regular expressions pattern to do this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | @staticmethod def _tokenize_words(message): ''' DESCRIPTION -------------- returns a list of unique words found within a message words are considered to be containing letters, numbers, single apostrophes and dashes PARSMETERS ------------- message: a string we wish to tokenize ''' # extract single words words = re.findall(r"[a-z0-9'-]+", message, re.IGNORECASE) # make them lower case and return unique list return set(word.lower() for word in words) |
We will load the data to our class as a list of tuples, where the first element of the tuple tells us where the message is spam or not and the second item represents the message itself. So we will need a function which, for each message, keeps track of the number of spam messages, the number of non spam message and the number of occurrences of each word within spam message and within non spam messages.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 | def _add_messages(self, messages): ''' DESCRIPTION ---------- keeps a tally of the words appearing in each message and of the overall spam and non-spam messages. self._words_count is a dict where each element is a two-elements lists. The first element of the list keeps a tally of the spam messages in which the key word appeared, the second element of the list keeps a tally of the non spam messages in which the key word appeared PARAMETERS --------- messages: a list of tuples, where the first element is either True (spam message) or False (non spam message) and the second element is the message itself RETURNS --------- None ''' for is_spam, message in messages: # add counts based on the category if is_spam: self._number_of_spam_messages += 1 else: self._number_of_non_spam_messages += 1 # tokenize words words = self._tokenize_words(message) for word in words: if is_spam: self._words_count[word][0] += 1 else: self._words_count[word][1] += 1 self._recalculate_probabilities() def _recalculate_probabilities(self): ''' DESCRIPTION ----------- recalculates the conditional probability of each word given spam and given not spam to avoid the issue of when a probability is zero (which would result into a zero product) we will use additive smoothing: https://en.wikipedia.org/wiki/Additive_smoothing ''' for word, (spam_count, non_spam_count) in self._words_count.items(): # the probability of a spam message containing word X self._words_probabilities[word][0] = ( 0.5 + spam_count) / (1 + self._number_of_spam_messages) # the probability of a non spam message containing word X self._words_probabilities[word][1] = ( 0.5 + non_spam_count) / (1 + self._number_of_non_spam_messages) |
and now we just need to add the last method which tells us the probability of a message being spam:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | def probability_spam(self, message): ''' DESCRIPTION ----------- returns the probability of a message being spam adds the natural logarithm of each probability PARAMETERS ---------- a message string RETURNS --------- the probability of message being spam ''' spam_probability = math.log((0.5 + self._number_of_spam_messages) / ( 1 + self._number_of_spam_messages + self._number_of_non_spam_messages)) non_spam_probability = math.log((0.5 + self._number_of_non_spam_messages) / ( 1 + self._number_of_spam_messages + self._number_of_non_spam_messages)) # extract unique words from message words_in_message = self._tokenize_words(message) for word, (word_spam_prob, word_non_spam_prob) in self._words_probabilities.items(): # if word is found in words_in_message then add the log in base e of the probabilities # of word appearing in a spam message and word appearinging in a non spam message if word in words_in_message: spam_probability += math.log(word_spam_prob) non_spam_probability += math.log(word_non_spam_prob) # if word is found in words_in_message then add the log in base e of the probabilities # of word not appearing (1-probability of appearing in a spam message) in a spam message # and word not appearing in a non spam message (1-probability of appearing in a non spam message) else: spam_probability += math.log(1.0 - word_spam_prob) non_spam_probability += math.log(1.0 - word_non_spam_prob) return math.exp(spam_probability) / (math.exp(spam_probability) + math.exp(non_spam_probability)) |
Testing the model
To test our model, we will first create a simple function which will split the data into a training set and a testing set:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | def split_train_test(data: list, test_size: float=0.4): ''' DESCRIPTION ----------- divides data into a training set and a testing set test_size is used to define the % of data which should go into the testing set PARAMETERS ---------- a list RETURNS ---------- a tuple where the first element is the training set ans the second element is the testing set ''' # % must be between 0.1 and 0.99 if not 0.99 > test_size > 0.1: raise ValueError('test_size must be between 0.1 and 0.99') test_size_int = int(test_size * 100) train_data = [] test_data = [] for row in data: if random.randint(1, 100) <= test_size_int: test_data.append(row) else: train_data.append(row) return train_data, test_data |
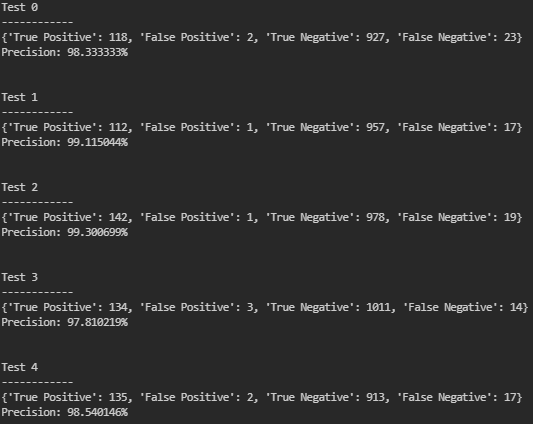
after testing the model a few times, we can see it outputs a very high precision:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 | import re from collections import defaultdict import math import random class SpamFilter(object): def __init__(self): self._number_of_spam_messages = 0 self._number_of_non_spam_messages = 0 self._words_count = defaultdict(lambda: [0, 0]) self._words_probabilities = defaultdict(lambda: [0.0, 0.0]) @staticmethod def _tokenize_words(message): ''' DESCRIPTION -------------- returns a list of unique words found within a message words are considered to be containing letters, numbers, single apostrophes and dashes PARSMETERS ------------- message: a string we wish to tokenize ''' # extract single words words = re.findall(r"[a-z0-9']+", message, re.IGNORECASE) # make them lower case and return unique list return set(word.lower() for word in words) def _add_messages(self, messages): ''' DESCRIPTION ---------- keeps a tally of the words appearing in each message and of the overall spam and non-spam messages. self._words_count if a dict where each element is a two-elements lists. The first element of the list keeps a tally of the spam messages in which the key word appeared, the second element of the list keeps a tally of the non spam messages in which the key word appeared PARAMETERS --------- messages: a list of tuples, where the first element is either True (spam message) or False (non spam message) and the second element is the message itself RETURNS --------- None ''' for is_spam, message in messages: # add counts based on the category if is_spam: self._number_of_spam_messages += 1 else: self._number_of_non_spam_messages += 1 # tokenize words words = self._tokenize_words(message) for word in words: if is_spam: self._words_count[word][0] += 1 else: self._words_count[word][1] += 1 self._recalculate_probabilities() def _recalculate_probabilities(self): ''' DESCRIPTION ----------- recalculates the conditional probability of each word given spam and given not spam to avoid the issue of when a probability is zero (which would result into a zero product) we will use additive smoothing: https://en.wikipedia.org/wiki/Additive_smoothing ''' for word, (spam_count, non_spam_count) in self._words_count.items(): # the probability of a spam message containing word X self._words_probabilities[word][0] = ( 0.5 + spam_count) / (1 + self._number_of_spam_messages) # the probability of a non spam message containing word X self._words_probabilities[word][1] = ( 0.5 + non_spam_count) / (1 + self._number_of_non_spam_messages) def train(self, messages): self._add_messages(messages) def probability_spam(self, message): ''' DESCRIPTION ----------- returns the probability of a message being spam adds the natural logarithm of each probability PARAMETERS ---------- a message string RETURNS --------- the probability of message being spam ''' spam_probability = math.log((0.5 + self._number_of_spam_messages) / ( 1 + self._number_of_spam_messages + self._number_of_non_spam_messages)) non_spam_probability = math.log((0.5 + self._number_of_non_spam_messages) / ( 1 + self._number_of_spam_messages + self._number_of_non_spam_messages)) # extract unique words from message words_in_message = self._tokenize_words(message) for word, (word_spam_prob, word_non_spam_prob) in self._words_probabilities.items(): # if word is found in words_in_message then add the log in base e of the probabilities # of word appearing in a spam message and word appearinging in a non spam message if word in words_in_message: spam_probability += math.log(word_spam_prob) non_spam_probability += math.log(word_non_spam_prob) # if word is found in words_in_message then add the log in base e of the probabilities # of word not appearing (1-probability of appearing in a spam message) in a spam message # and word not appearing in a non spam message (1-probability of appearing in a non spam message) else: spam_probability += math.log(1.0 - word_spam_prob) non_spam_probability += math.log(1.0 - word_non_spam_prob) return math.exp(spam_probability) / (math.exp(spam_probability) + math.exp(non_spam_probability)) def split_train_test(data: list, test_size: float=0.4): ''' DESCRIPTION ----------- divides data into a training set and a testing set test_size is used to define the % of data which should go into the testing set PARAMETERS ---------- a list RETURNS ---------- a tuple where the first element is the training set ans the second element is the testing set ''' # % must be between 0.1 and 0.99 if not 0.99 > test_size > 0.1: raise ValueError('test_size must be between 0.1 and 0.99') test_size_int = int(test_size * 100) train_data = [] test_data = [] for row in data: if random.randint(1, 100) <= test_size_int: test_data.append(row) else: train_data.append(row) return train_data, test_data if __name__ == '__main__': messages = [] # read the txt file with open('SMSSpamCollection.txt', mode='r', encoding='UTF-8') as spam_file: for line in spam_file: category, message = line.split('\t', maxsplit=1) messages.append((category=='spam', message)) # split data into training and testing train, test = split_train_test(messages, 0.2) # train the model s = SpamFilter() s.train(train) # test the model stats = {'True Positive': 0, 'False Positive': 0, 'True Negative': 0, 'False Negative': 0} for is_spam, message in test: spam_prob = s.probability_spam(message) > 0.5 if spam_prob: if is_spam: stats['True Positive'] += 1 else: stats['False Positive'] +=1 else: if is_spam: stats['False Negative'] += 1 else: stats['True Negative'] += 1 print(stats) print('Precision: {0:.2%}'.format(stats['True Positive'] / (stats['True Positive'] + stats['False Positive']))) |
Download files here: https://github.com/LivioLanzo/Naive-Bayes-Spam-Filter